Jun-Peng Zhu
Short Biography
Jun-Peng Zhu received his Ph.D. degree from the School of Data Science and Engineering, East China Normal University. He was selected for the National Key Software High-level Talent Doctoral Program jointly administered by the Ministry of Education and the Ministry of Industry and Information Technology. He is fortunate to work closely with Prof. Peng Cai, Prof. Xuan Zhou, Prof. Aoying Zhou and Dr. Kai Xu. His research interests span various database topics, with a current focus on data analysis systems through LLMs and distributed database systems. He is also exploring AI for Science applications in areas such as bioinformatics and healthcare. He worked as an R&D engineer in the TiDB Cloud Platform Group at PingCAP, focusing on autonomous services for TiDB, under the supervision of Dr. Kai Xu, Liu Tang, and Qi Liu. Previously, he worked as a kernel R&D engineer at the VMware Greenplum database team, focusing on nested transactions and query optimization for MPP distributed database systems. He has published more than ten papers at top-tier international database conferences in the field of data management, such as SIGMOD, VLDB, and ICDE. Feel free to reach out for potential collaborations.
Research Interests
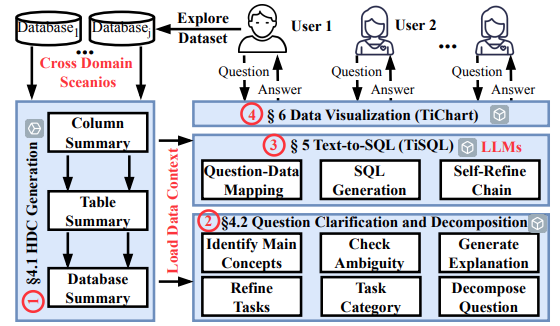
- Automated Data Analysis Systems: TiInsight (PVLDB'25), UNITQA (SIGMOD'25), Chat2Query (ICDE'24), AutoTQA (PVLDB'24)
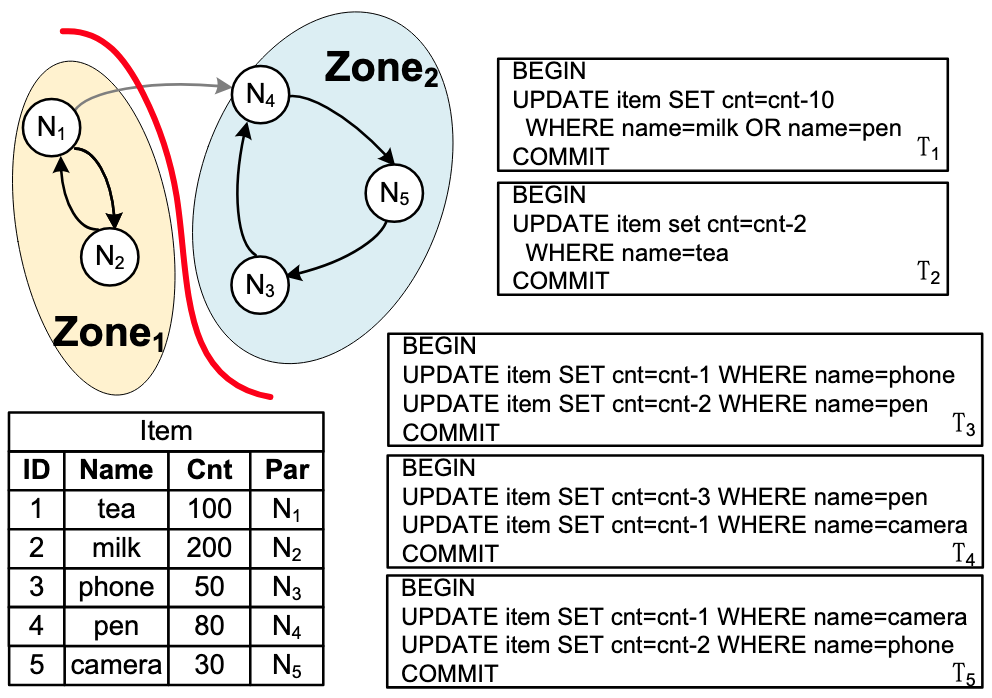
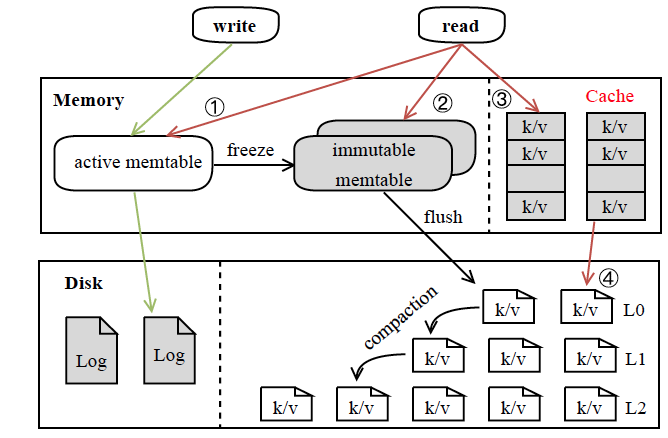
- Distributed Database Systems: RedTAO (SIGMOD'25), SylphDB (ICDE'25), FDBKeeper (PVLDB'25), HAWK (PVLDB'25), AETS (ICDE'24)
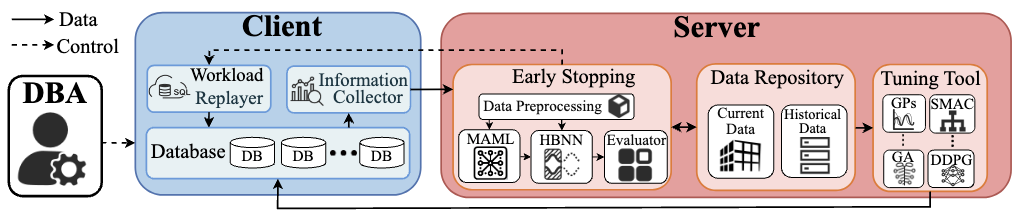
- AI for Database Systems: ESTune (SIGMOD'26), MODT (DASFAA'24), AutoTable (WISE'24)
News
- [Dec. 2025] One paper about AI for Automated Seizure Detection won the Best Paper Award at IEEE BDDM! Congratulations! 🎉🎉🎉
- [Nov. 2025] One paper about database configuration tuning is accepted to SIGMOD 2026. Congratulations! 🎉🎉🎉
- [Sep. 2025] Attended VLDB 2025@London, United Kingdom. 🎉🎉🎉
- [Jun. 2025] One paper about exploratory data analysis is accepted to VLDB 2025. Congratulations! 🎉🎉🎉
- [Jun. 2025] One paper about coordination service is accepted to VLDB 2025. Congratulations! 🎉🎉🎉
- [Jun. 2025] One paper about deadlock detection is accepted to VLDB 2025. Congratulations! 🎉🎉🎉
- [May. 2025] Attended ICDE 2025@Hong Kong SAR, China. 🎉🎉🎉
- [Mar. 2025] One paper about tabular question answering system is accepted to SIGMOD 2025. Congratulations! 🎉🎉🎉
- [Mar. 2025] One paper about graph store is accepted to SIGMOD 2025. Congratulations! 🎉🎉🎉
- [Mar. 2025] One paper about LSM-tree optimization is accepted to ICDE 2025. Congratulations! 🎉🎉🎉
- [Dec. 2024] One paper about cross-domain exploratory data analysis is uploaded to arXiv. 🎉🎉🎉
- [Aug. 2024] Attended VLDB 2024@Guangzhou, China. 🎉🎉🎉
- [Jun. 2024] One paper about tabular question answering is accepted to VLDB 2024. Congratulations! 🎉🎉🎉
- [May. 2024] Attended ICDE 2024@Utrecht, Netherlands. 🎉🎉🎉
- [Feb. 2024] One paper about exploratory data analysis is accepted to ICDE 2024. Congratulations! 🎉🎉🎉
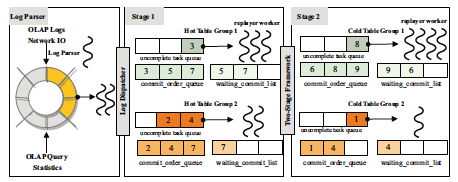
- [Dec. 2023] One paper about log replaying for HTAP workloads is accepted to ICDE 2024. Congratulations! 🎉🎉🎉
Selected Publications [View All]
For more details, please view the Google Scholar profile.
2026
-
 SIGMOD
ACM SIGMOD/PODS International Conference on Management of Data (SIGMOD), 2026CCF-A
SIGMOD
ACM SIGMOD/PODS International Conference on Management of Data (SIGMOD), 2026CCF-A
2025
-
 BDDM
IEEE International Conference on Big Data and Data Mining, 2025Best Paper Award
BDDM
IEEE International Conference on Big Data and Data Mining, 2025Best Paper Award -
 PVLDB
Proceedings of the VLDB Endowment (PVLDB), 2025.CCF-A
PVLDB
Proceedings of the VLDB Endowment (PVLDB), 2025.CCF-A -
 PVLDB
Proceedings of the VLDB Endowment (PVLDB), 2025.CCF-A
PVLDB
Proceedings of the VLDB Endowment (PVLDB), 2025.CCF-A -
 PVLDB
Proceedings of the VLDB Endowment (PVLDB), 2025.CCF-A
PVLDB
Proceedings of the VLDB Endowment (PVLDB), 2025.CCF-A -
 ICDE
41st IEEE International Conference on Data Engineering (ICDE), 2025CCF-A
ICDE
41st IEEE International Conference on Data Engineering (ICDE), 2025CCF-A -
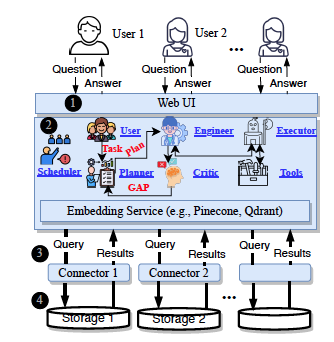 SIGMOD
UNITQA: A Unified Automated Tabular Question Answering System with Multi-Agent Large Language ModelsACM SIGMOD/PODS International Conference on Management of Data (SIGMOD), 2025CCF-A
SIGMOD
UNITQA: A Unified Automated Tabular Question Answering System with Multi-Agent Large Language ModelsACM SIGMOD/PODS International Conference on Management of Data (SIGMOD), 2025CCF-A -
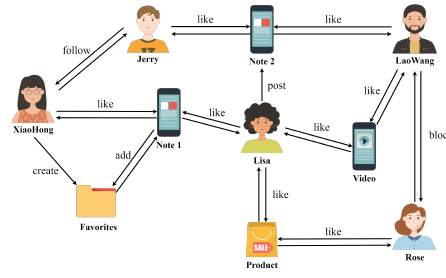 SIGMOD
ACM SIGMOD/PODS International Conference on Management of Data (SIGMOD), 2025CCF-A
SIGMOD
ACM SIGMOD/PODS International Conference on Management of Data (SIGMOD), 2025CCF-A
2024
-
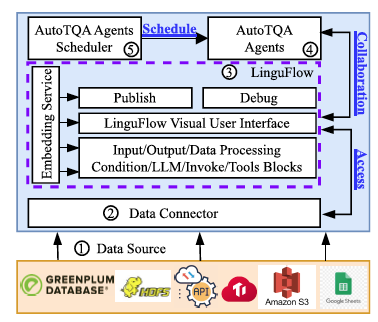 PVLDB
Proceedings of the VLDB Endowment (PVLDB), 2024.CCF-A
PVLDB
Proceedings of the VLDB Endowment (PVLDB), 2024.CCF-A -
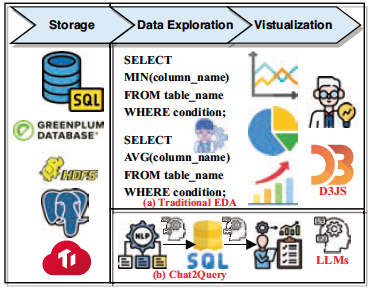 ICDE
2024 IEEE 40th International Conference on Data Engineering (ICDE), 2024.CCF-A
ICDE
2024 IEEE 40th International Conference on Data Engineering (ICDE), 2024.CCF-A
2023
-
 ICDE
2024 IEEE 40th International Conference on Data Engineering (ICDE), 2024.CCF-A
ICDE
2024 IEEE 40th International Conference on Data Engineering (ICDE), 2024.CCF-A
Services
Conference Reviewers
- European Conference on Computer Systems (EuroSys 2026)
- 2025 IEEE BDDM session chair and reviewer
- International Conference on Database Systems for Advanced Applications (DASFAA 2024/2025/2026)
- ACM International Conference on Information and Knowledge Management (CIKM 2024)
Journal Reviewers
- IEEE Transactions on Knowledge and Data Engineering (TKDE)
Experience
Database R&D Engineer
- PingCAP, TiDB Cloud Platform Team
Database Kernel R&D Engineer
- VMware, Greenplum Database Team
Honors and Awards
- East China Normal University Presidential Scholarship (highest honor for Ph.D. students at East China Normal University), 2025
- Excellent Student Cadre of ECNU, 2025
- Ph.D Industrial First Class Scholarship, 2025
- Ph.D National Scholarship, 2024
- "Hack Split Insert for Greenplum" won the bronze medal at the VMware Global Hackathon, 2022
Visitors
